您现在的位置是:主页 > news > 一个网站能用asp c/个人开发app去哪里接广告
一个网站能用asp c/个人开发app去哪里接广告
![]() admin2025/5/1 12:58:08【news】
admin2025/5/1 12:58:08【news】
简介一个网站能用asp c,个人开发app去哪里接广告,node.js可以做网站,聊城集团网站建设多少钱第一次在知乎写文章,想谈谈博士期间比较熟悉的视觉目标跟踪。过去每一年的这个时候都在忙碌的赶CVPR,今年突然闲下来,有点不适。工作之余,写点文章当作是怀念科研的时光。步入正题,谈谈最近在CVPR2021和ICCV2021上看到…
第一次在知乎写文章,想谈谈博士期间比较熟悉的视觉目标跟踪。过去每一年的这个时候都在忙碌的赶CVPR,今年突然闲下来,有点不适。工作之余,写点文章当作是怀念科研的时光。步入正题,谈谈最近在CVPR2021和ICCV2021上看到的几篇无监督单目标跟踪算法。
单目标跟踪任务,给定初始目标的位置和尺寸,要求跟踪器持续地对目标进行定位。不同于多目标跟踪,单目标跟踪要求可以处理任意的物体,而多目标跟踪通常是固定类别的物体,如行人、车辆等。因此,单目标跟踪算法的这种“物体不定性”就好比一把双刃剑,一方面,待跟踪物体包罗万象,各种奇奇怪怪的物体为该任务带来诸多挑战;另一方面,不限制目标类别,又为跟踪任务的建模和训练带来无限可能。
早年间,相关滤波器统治跟踪领域时,基于局部的相关滤波器算法将物体划分成小块,并对小块进行逐帧跟踪。曾让我惊讶的是,这些细小的目标(比如一个人的衣角、身体局部)等仍然可以在较短的时间内跟踪的不错。后续算法甚至跟踪目标的边缘,以实现跟踪框的自适应变化。既然跟踪器被要求跟踪任意的物体,包括不规则物体、物体局部、物体边缘等,那么在模型训练时是否真的需要标注一个个明确的物体?我们是否可以在深度学习时代,无监督地训练深度跟踪器?
UDT (CVPR 2019)
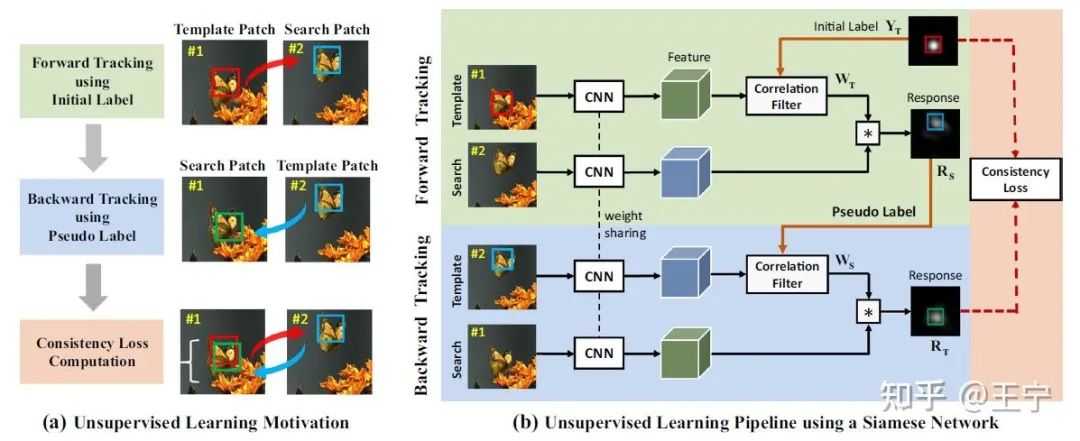
在“Unsupervised Deep Tracking”[1]中,基于跟踪器对于物体类别不敏感的这种特性以及物体在是视频中的时序特性,我曾经将DCFNet算法[2]进行了无监督训练。基本出发点在于,随机选择视频中的一个区域,对其进行前向和反向跟踪,并依据前后跟踪轨迹的一致性进行模型的训练。第一版实验结果便出乎我的意料,随意选择视频中的一个区域作为目标,进行无监督训练,就可以将DCFNet训练的还不错。我知道,这一方面源于Correlation Filter的强大辨别能力,哪怕将图片变为灰度图怼进去,DCF也能跟踪的七七八八,何况现在又训练了一个CNN作为特征提取网络。
但当初让我惊讶的点在于,在ILSVRC2015中即便使用随意选取的目标(或者说是图片中随意的区域),无监督训练的结果也仅仅和全监督相差5~6点的AUC。后面又增加了一些trick,引入多帧无监督训练,修改loss函数等,又将DCFNet的无监督训练和全监督训练的性能差距缩小到3% AUC。
UDT算法的流程示意图
其实当初选择DCFNet作为Baseline有很大的私心,因为我知道DCF的强大辨别能力以及在后端可以设计trick并调整各种超参数(比如跟踪尺度惩罚因子、DCF学习率等),使得无监督算法的性能有基础的保障,快速水一篇论文,赶上当年的CVPR deadline。当时由于时间的紧迫,很多实验也并没有测试。后续在期刊中(简记LUDT算法[3]),经过进一步的验证,无监督学习到的跟踪特征确实明显好于HOG等手工特征和自编码器等无监督特征,说明这种“前向-反向验证”的无监督训练模型学到了适合于跟踪任务的表征。
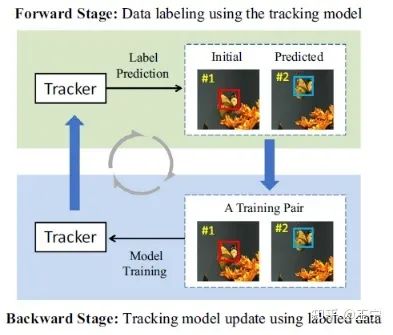
UDT这份工作仍然有一些不满意的地方。这篇文章的训练流程图看似行云流水,仿佛是一个end-to-end的框架,然后伪标签的生成部分是不可导的。实验中发现,直接将前向跟踪得到的response map作为反向跟踪器的标签效果极差。因此,伪标签生成时以前向结果再次生成标准的高斯分布作为反向跟踪的标签。
这样,整个forward tracking部分就如同于在标数据,backward tracking部分在利用前向标注的数据进行DCFNet的训练。只是在不断训练过程中,模型逐步挖掘到好的训练样本,逐步提升跟踪能力,周而复始,前向跟踪的标注越来越好,后向跟踪持续提升跟踪能力。整个过程如下图所示。另外,我当时也很想知道SiamFC等算法是否同样可以无监督训练并达到优异结果,因为我知道设计的UDT算法性能有DCF的加持,而单纯的SiamFC跟踪器更加考验网络的表征能力。但后来时间仓促,也不了了之。
PUL (CVPR 2021)
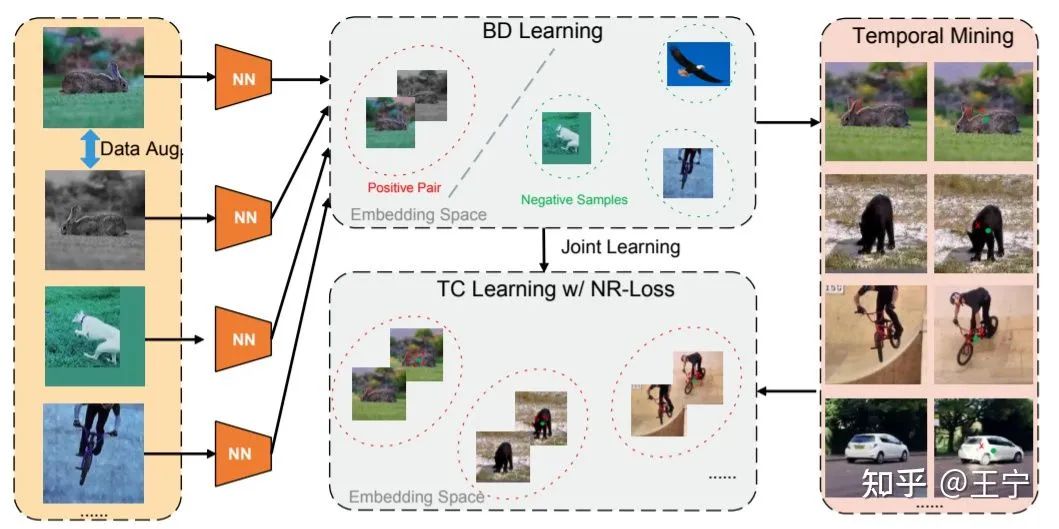
直到最近,在2021年的CVPR和ICCV上都看到了无监督跟踪的论文,又再次认真研究起来。在“Progressive Unsupervised Learning for Visual Object Tracking” (CVPR 2021)一文中(简记PUL算法[4]),作者首先使用contrastive learning学到到如何前景、背景区分的能力。在经典的训练数据集ILSVRC 2015中,PUL算法首先使用EdgeBox生成高质量的proposal,并借助前景、背景区分模块进行时序上的训练样本收集。
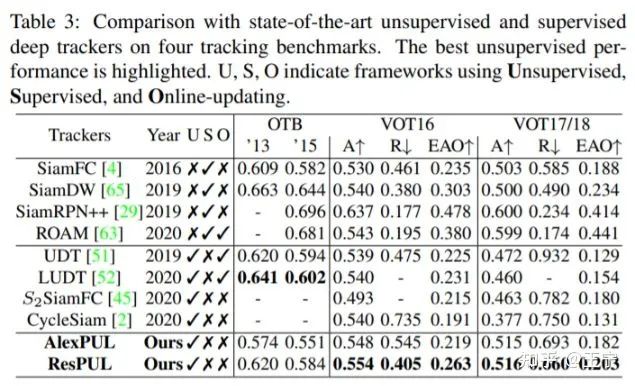
最后,由于这些无监督收集到的样本无可避免的存在噪声,作者又重新优化了SiamFC的loss function,以适应当前的无监督数据。该论文主要仍然针对两方面优化无监督跟踪训练:数据采集和模型训练。数据采集上,借助EdgeBox和contrastive model,PUL算法得到了更高质量的无监督样本,相比于UDT的随机采集和LUDT的基于图片熵的选取要好很多。该工作取得了相当优异的性能,相比于全监督的SiamFC并没有落后很多,证明了学习到的特征表达的鲁棒性。
PUL算法示意图
PUL算法对比结果
USOT (ICCV 2021)
在“Learning to Track Objects from Unlabeled Videos”(ICCV 2021)文章中(简记USOT算法[5])中,作者将无监督跟踪分成三个部分:数据生成、单帧训练、多帧训练。在数据生成部分,USOT采用无监督光流的ARFlow方法找到视频中的运动物体,并使用帧间的动态规划算法进行BBox的优化。相比于LUDT采用的图片熵、PUL采用的EdgeBox等基于内容、纹理选取目标区域的方法,USOT的数据处理更加用心,可以捕获运动目标以更适合于跟踪任务训练。
接下来,USOT在单帧内进行目标跟踪,即将目标和当前帧的搜索区域组成一组训练样本对,可以快速的学习到初始的跟踪能力。最后,为了挖掘时序上目标的外观变化,作者在视频帧间进行"前向-反向"跟踪,并将跟踪结果组成memory queue,并学习不同的目标样本如何加权,为在线跟踪阶段的模型更新做好准备。
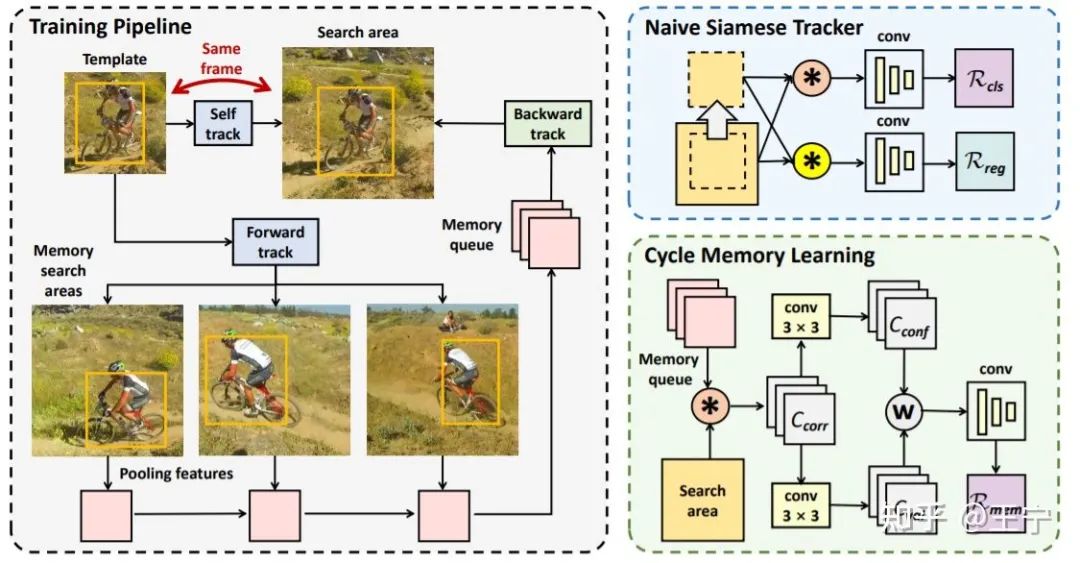
USOT算法示意图
USOT的基线算法是更加先进的双路网络,Anchor-free Siamese Tracker: Ocean [6]。有些出乎我的意料,因为无监督样本的噪声很大,目标框很难准确地、紧密地包含物体,导致目标框的回归问题格外困难。我曾经想尝试无监督地训练ATOM [8]中的IOUNet,但最后结果不够理想,也不了了之。我猜测USOT可能基于高质量的光流BBox以及帧内训练,使得目标尺度回归变为可能。
该工作的"cycle memory training"很可能一定程度受启发于Ocean算法,在无监督训练时学习额外的加权模型,便于在线跟踪时利用template memory加权更新外观模型。相比于LUDT、PUL等,USOT使用了更多的无监督数据,包含GOT-10k、ImageNet-VID、LaSOT、Youtube VOS等、直接对标SiamRPN++ [7]、DiMP [9]等工作。另外该方法对于时序帧的利用也更加充分,可以前向-反向探索40~60帧的长度,远超LUDT的10帧左右。
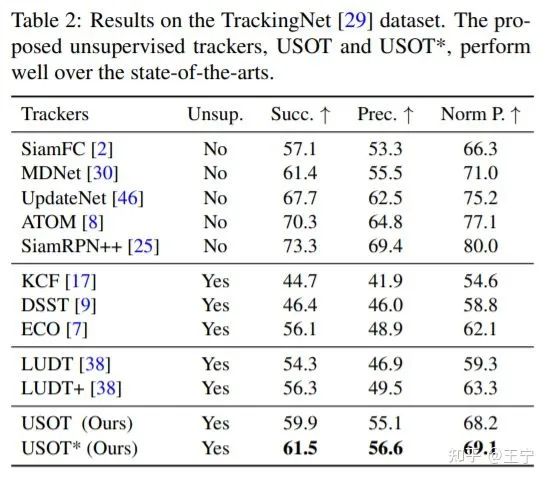
USOT算法在TrackingNet上的对比结果
![]()
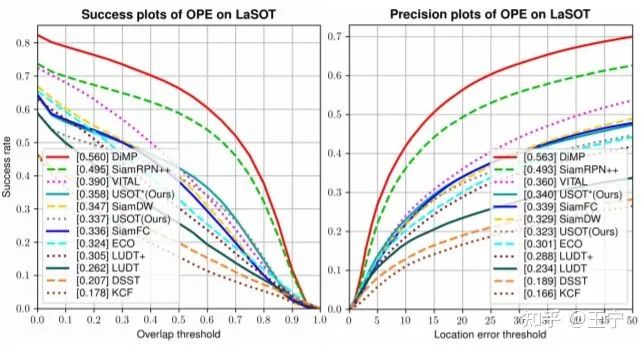
USOT算法在LaSOT上的对比结果
USOT论文列举了它自己的贡献:如运动目标挖掘、单帧探索和帧间探索相结合、cycle memory mining等。但在我看来,他更重要的贡献是将无监督跟踪器朝着网络更深、数据规模更大的方向演进、朝着目标尺度回归的方向演进,我个人认为这些尝试是无监督跟踪算法性能提升的必经之路,也是尤为重要的。特别是BBox Regression,我认为这是全监督和无监督跟踪器performance gap的主要症结所在。USOT的性能相比于LUDT有大幅度的提升,这不出乎我的意料。但是在LaSOT数据集中,USOT算法的性能仍远低于SiamRPN++ [7]、ATOM [8]等算法。
从我个人的经验看来,尺度回归的准确性对于LaSOT的性能提升十分巨大,我相信LaSOT上大部分AUC 30+%的跟踪器的前景-背景的区分能力都不弱(如MDNet、ECO、SiamDW),它们和AUC 50%左右的跟踪器可能就差一个IOUNet或者RPN结构。我也曾经尝试过将MDNet加上ATOM的IOUNet,性能瞬间提升10%左右。
从另外一个角度,我们可以将ATOM和USOT*进行对比。AOTM的classification分支没有经过离线训练(类似于相关滤波器的岭回归在线优化过程),仅仅只有一个IOUNet需要训练,便性能SOTA。而使用了ImageNet上全监督训练的Resnet backbone的 USOT*算法在LaSOT的AUC性能为35%左右,和ATOM足足差了15%,我猜测这两者最主要的gap还是在于目标的尺度回归能力。
小结
无监督跟踪算法的优化和提升仍然任重道远。最后随便写点感想:
无监督任务最吸引人的魅力就在于无需标注成本,当训练数据的规模呈现数量级的突破时,往往会出现意想不到的事情。例如最近的CLIP、ALIGN等基于多模态的预训练算法,简单粗暴,但确实让人惊讶。而无监督跟踪是否同样有这样的潜力呢?
目标尺度的回归仍然是一个重要问题。我相信样本数据充分挖掘的时候,跟踪器的区分能力不再是瓶颈,更何况跟踪领域从来不缺few-shot classification的建模能力(诸如各种类型的相关滤波器,few-shot网络等)。但从无标注视频中获取高质量的尺度回归能力仍是一个开放性问题。我曾经结合过unsupervised correspondence learning进行pixle-level的跟踪,并将patch-level VOT和pixel-level VOS结合起来,但效果也不够理想。回到文章开头的问题"跟踪模型训练是否需要明确的物体标注?"我想对于跟踪器的区分能力提升,可能并不迫切,正好比正负样本的contrastive learning也从来不要求是目标严丝合缝的矩形框。但是,对于尺度回归呢,无标注视频中的局部物体,语义不明确物体,对回归网络带来的噪声该如何避免?
此外,我曾经思考无监督跟踪能为跟踪领域带来什么,一篇有点创新但跟踪效果远远不够的算法?无监督跟踪训练的价值还有待于挖掘。能否通过大规模的无监督跟踪的预训练,得到高质量的、鲁棒的、适合于VOT、VOS的特征表达,并提升一系列的下游子任务(例如模板匹配、VOT、VOS、光流相关任务)?那样将会极大地提升无监督跟踪训练的意义。就好比与BERT的预训练之于各种NLP任务,Vision+Language的预训练对于各种多模态下游任务一样。无监督学习的特征虽然目前还不足够鲁棒,但大规模训练后,是否可以作为跟踪器backbone的更好的初始化参数?
最后,还想聊聊无监督跟踪训练和无监督的correspondence learning之间千丝万缕的联系,但是限于篇幅,有空再更吧。上述仅是个人浅薄的观点,如有错误敬请指正。
参考文献
[1] N. Wang, et al. Unsupervised Deep Tracking. In CVPR, 2019.
[2] Q. Wang, et al. DCFNet: Discriminant Correlation Filters Network for Visual Tracking. arXiv:1704.04057, 2017.
[3] N. Wang, et al. Unsupervised Deep Representation Learning for Real-Time Tracking. IJCV, pages 1–19, 2020.
[4] Q. Wu, et al. Progressive Unsupervised Learning for Visual Object Tracking. In CVPR, 2021.
[5] J. Zheng, et al. Learning to Track Objects from Unlabeled Videos. In ICCV, 2021.
[6] Z. Zhang, et al. Ocean: Object-aware Anchor-free Tracking. In ECCV, 2020.
[7] B. Li, et al. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks. In CVPR, 2019.
[8] M. Danelljan, et al. ATOM: Accurate Tracking by Overlap Maximization. In CVPR, 2019.
[9] G. Bhat, et al. Learning Discriminative Model Prediction for Tracking. In ICCV, 2019.
作者:王宁
|深延科技|
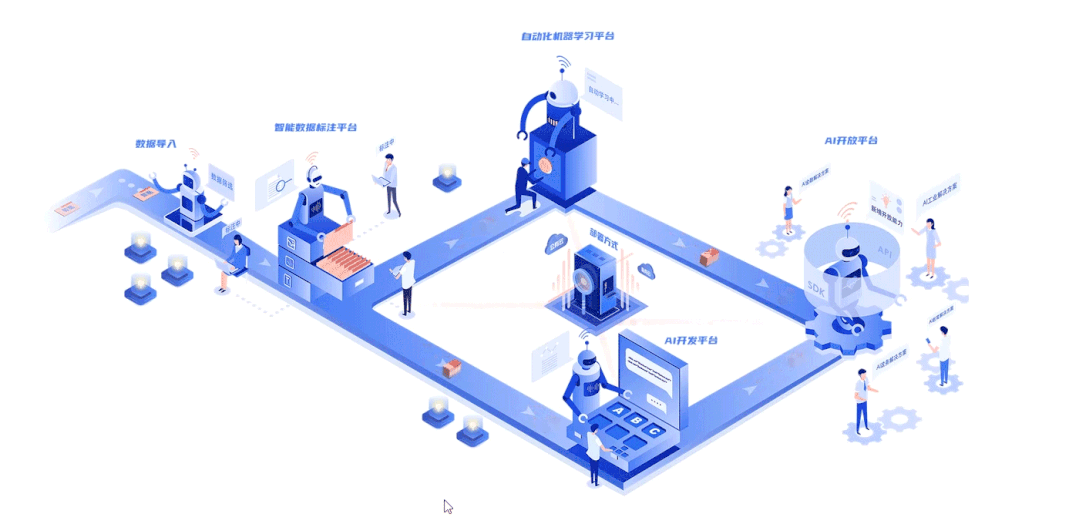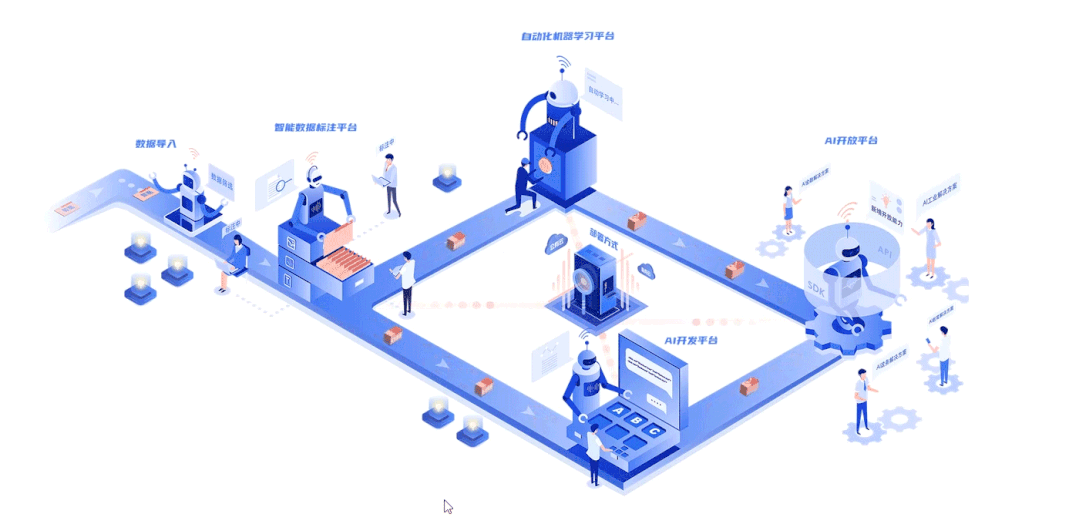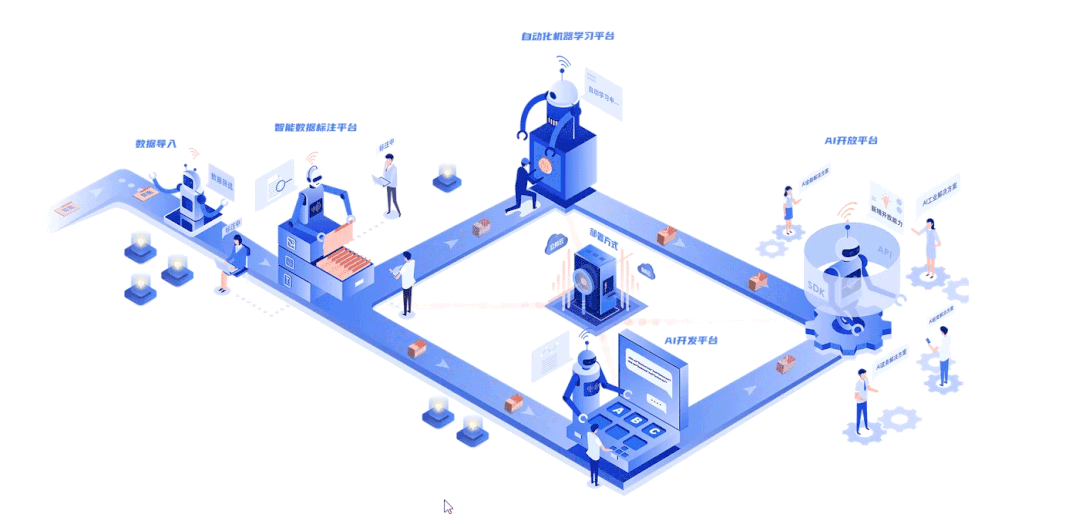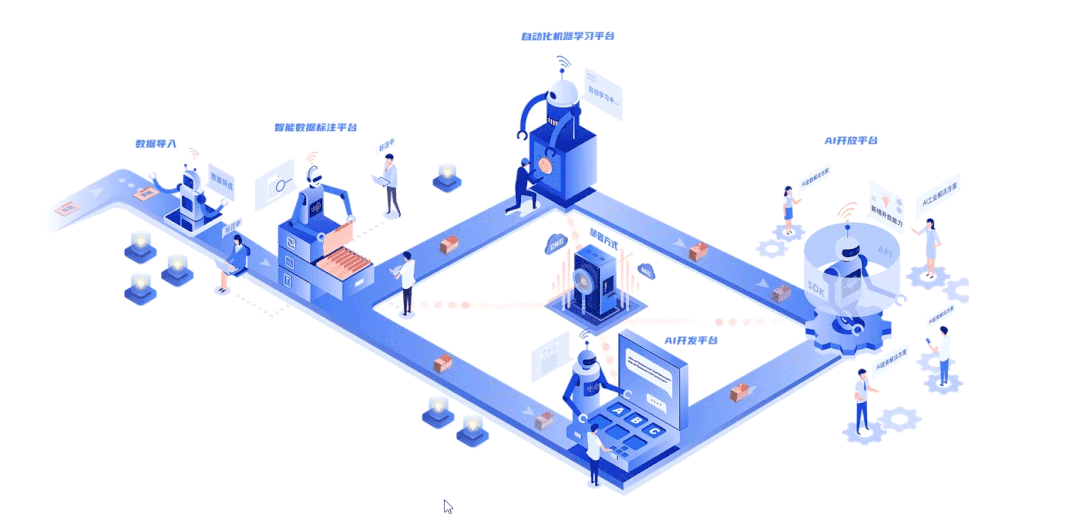
深延科技成立于2018年,是深兰科技(DeepBlue)旗下的子公司,以“人工智能赋能企业与行业”为使命,助力合作伙伴降低成本、提升效率并挖掘更多商业机会,进一步开拓市场,服务民生。公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,涵盖从数据标注及处理,到模型构建,再到行业应用和解决方案的全流程服务,一站式助力企业“AI”化。








