您现在的位置是:主页 > news > 模板网站建设多少钱/廊坊百度推广电话
模板网站建设多少钱/廊坊百度推广电话
![]() admin2025/5/4 11:02:25【news】
admin2025/5/4 11:02:25【news】
简介模板网站建设多少钱,廊坊百度推广电话,可以写代码的网站有哪些问题吗,5156智通人才招聘网Combiner Combiner概述 Combiner类是用来优化MapReduce的,在MapReduce的Map环节,会产生大量的数据,Combiner的作用就是在map端先对这些数据进行简单的处理,减少传输到Reduce端的数据量,从而提高MapReduce的运行效率。…
Combiner
Combiner概述
Combiner类是用来优化MapReduce的,在MapReduce的Map环节,会产生大量的数据,Combiner的作用就是在map端先对这些数据进行简单的处理,减少传输到Reduce端的数据量,从而提高MapReduce的运行效率。
Combiner并没有自己的基类,他是继承Reducer的,对外功能一样。
他们的区别是,Combiner操作发生在Map端,在某些情况下Combiner的加入不会影响程序的运行结果,只会影响效率。
以下Combiner代码基于WordCount词频获取 编写。
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class wccombiner extends Reducer<Text, IntWritable,Text,IntWritable> {int sum;IntWritable v =new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {//reduce端接收到的类型大概是 (wish,(1,1,1,1,1,1,1))sum=0;//遍历迭代器for (IntWritable count : values) {//对迭代器进行累加求和sum+=count.get();}//将key和value进行写出v.set(sum);context.write(key,v);}
}我们通过对比发现,他与Reducer的代码一致,没啥区别。
Partitioner
Partitioner概述
Partitioner的功能是在Map端对key进行分区,即对key值进行分门别类。
比如说基于MapRuduce的手机号获取这个实例里,
我们想要对得到的手机号进行区域归属地的划分,这里我们就需要用到Partitioner。
其使用代码如下所示:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;public class ProvincePartitioner extends Partitioner<Text,FlowBean> {@Overridepublic int getPartition(Text key, FlowBean value, int i) {//1.取出手机号的前三位String preNum=key.toString().substring(0,3);int partition=4;//2.判断属于哪一个省的,返回分区号if ("136".equals(preNum)){partition=0;}else if ("137".equals(preNum)){partition=1;}else if ("138".equals(preNum)){partition=2;}else if ("139".equals(preNum)){partition=3;}return partition;}
}在这里我们只统计136-139号码的归属地,其他所有的手机号,都会一起被存放在另一个单独的文件中。
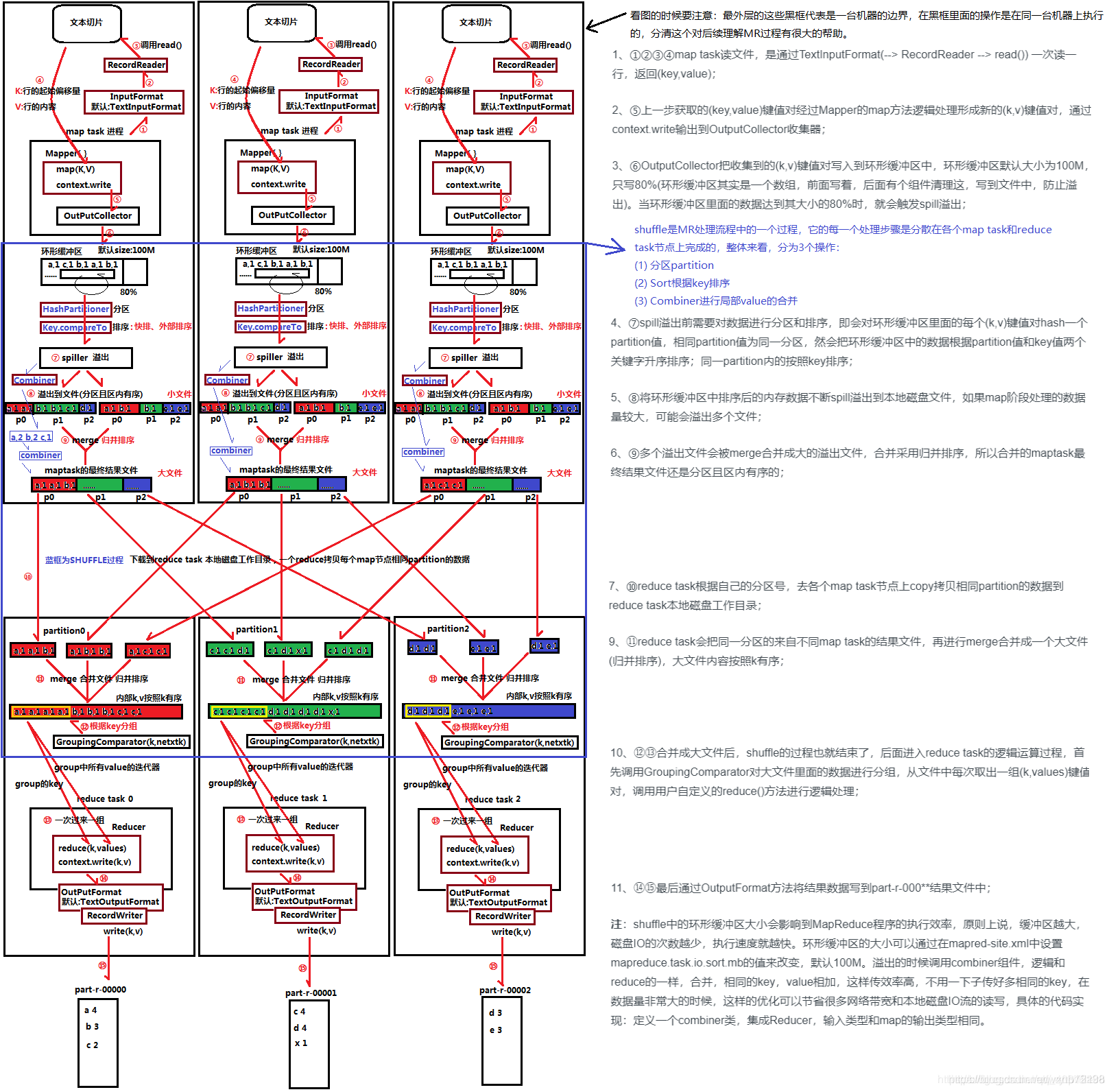
Shuffle
Shuffle概述
Shuffle阶段是MapReduce最为核心的阶段,他的大致处理过程就是把Map的结果有效的传递到Reduce端。
Shuffle阶段分为Map端的Shuffle和Reduce端的Shuffle,以下分别介绍两个阶段以及原理。
1.Map的Shuffle
Map端的Shuffle过程如下所示:
- 拆分: InputSplit将作业拆分成多个Map任务。
- 执行自定义的map()方法:Map过程开始处理,Mapper任务会接受输入的分片,通过不断地调用map()方法对数据经行处理,这就是为什么Mapper文件和Reducer文件不用编写循环的原因。
- 缓存:Map的输出结果先写到内存的一个缓冲区。
- 分区(Partitioner):在内存中进行分区,默认是HashPartitioner,目的是将Map端的结果分给不同的Reducer。
- 排序:分区结束后,对不同区分的数据,根据key进行排序。
- 分组: 排序后按key进行分组,将相同的键值对<key,value>放在同一个分组。
- 合并(Combiner):合并分组后,如果设置了Combiner,就会合并数据,减少写入磁盘的记录数
- 溢写(Spill):当内存中的数据到达一定值时,系统会自动把记录写到磁盘中,形成spill文件。
- 合并文件: Map过程结束后,把溢写的spill文件合并成一个。
2.Reduce 端的Shuffle
- 复制过程: Ruduce端启动一些数据复制的线程,通过HTTP方式请求获取Map任务的文件。
- 合并阶段:与Map阶段的合并类似。但数据是从不同的Map端复制过来的
- Reducer的输入文件: 经过不断合并后,最终生成一个文件。当Reducer的输入文件已定,整个Shuffle过程结束。然后由Rudece执行,把结果放到HDFS上。
以下是MapReduce的原理图