您现在的位置是:主页 > news > 宁波网站建设公司排名/2022年新闻热点事件
宁波网站建设公司排名/2022年新闻热点事件
![]() admin2025/5/5 8:56:24【news】
admin2025/5/5 8:56:24【news】
简介宁波网站建设公司排名,2022年新闻热点事件,一键wifi免费上网,纪念平台网站建设Skip-gram的算法实现 Skip-gram的实际实现 在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W非常大。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务…
Skip-gram的算法实现
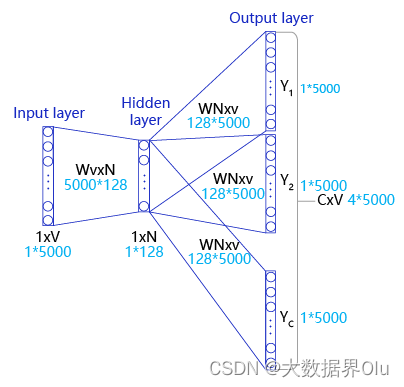
Skip-gram的实际实现
在实际情况中,vocab_size通常很大(几十万甚至几百万),导致W非常大。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务。
假设有一个中心词c和一个上下文词正样本tp。在Skip-gram的理想实现里,需要最大化使用c推理tp的概率。在使用softmax学习时,需要最大化tp 的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
- 代表中心词的tensor:假设我们称之为center_words VVV,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
- 代表目标词的tensor:假设我们称之为target_words TTT,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
- 代表目标词标签的tensor:假设我们称之为labels LLL,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
过程与使用CBOW类似,只有构造训练数据时的操作不同
笔记&实践 | 基于CBOW实现Word2Vec
#构造数据,准备模型训练
#max_window_size代表了最大的window_size的大小,程序会根据max_window_size从左到右扫描整个语料
#negative_sample_num代表了对于每个正样本,我们需要随机采样多少负样本用于训练,
#一般来说,negative_sample_num的值越大,训练效果越稳定,但是训练速度越慢。
def build_data(corpus, word2id_dict, word2id_freq, max_window_size = 3, negative_sample_num = 4):#使用一个list存储处理好的数据dataset = []center_word_idx=0#从左到右,开始枚举每个中心点的位置while center_word_idx < len(corpus):#以max_window_size为上限,随机采样一个window_size,这样会使得训练更加稳定window_size = random.randint(1, max_window_size)#当前的中心词就是center_word_idx所指向的词,可以当作正样本positive_word = corpus[center_word_idx]#以当前中心词为中心,左右两侧在window_size内的词就是上下文context_word_range = (max(0, center_word_idx - window_size), min(len(corpus) - 1, center_word_idx + window_size))context_word_candidates = [corpus[idx] for idx in range(context_word_range[0], context_word_range[1]+1) if idx != center_word_idx]#对于每个正样本来说,随机采样negative_sample_num个负样本,用于训练for context_word in context_word_candidates:#首先把(上下文,正样本,label=1)的三元组数据放入dataset中,#这里label=1表示这个样本是个正样本dataset.append((context_word, positive_word, 1))#开始负采样i = 0while i < negative_sample_num:negative_word_candidate = random.randint(0, vocab_size-1)if negative_word_candidate is not positive_word:#把(上下文,负样本,label=0)的三元组数据放入dataset中,#这里label=0表示这个样本是个负样本dataset.append((context_word, negative_word_candidate, 0))i += 1center_word_idx = min(len(corpus) - 1, center_word_idx + window_size)if center_word_idx == (len(corpus) - 1):center_word_idx += 1if center_word_idx % 100000 == 0:print(center_word_idx)return datasetdataset = build_data(corpus, word2id_dict, word2id_freq)
for _, (context_word, target_word, label) in zip(range(50), dataset):print("center_word %s, target %s, label %d" % (id2word_dict[context_word],id2word_dict[target_word], label))








