您现在的位置是:主页 > news > 营销型网站 开源程序/推广app用什么平台比较好
营销型网站 开源程序/推广app用什么平台比较好
![]() admin2025/5/7 7:41:30【news】
admin2025/5/7 7:41:30【news】
简介营销型网站 开源程序,推广app用什么平台比较好,怎样给网站增加栏目,如何引用404做网站背景数据量级数据数量:十亿级空间大小:百G级场景非实时性去重计算,如果每操作一条数据都要作重复性判断,目前可能以redis等内存数据库解决更佳,但是数据量过大带来直接问题就是,内存占用开销也是相当大的。…
背景
数据量级
数据数量:十亿级
空间大小:百G级
场景
非实时性去重计算,如果每操作一条数据都要作重复性判断,目前可能以redis等内存数据库解决更佳,但是数据量过大带来直接问题就是,内存占用开销也是相当大的。成本太高,只能寻找非redis等内存数据库的解决方案。
RocksDB
文档
官网:https://rocksdb.org/
github: https://github.com/facebook/rocksdb/
简介
RocksDB是 Facebook 开源的一个高性能、持久化、 KV 存储。数据存储采用的是一种叫做LSM-Tree(The Log-Structured Merge-Tree)的数据结果。
LSM是一种分层、有序且面向磁盘的实现,包含了 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table):
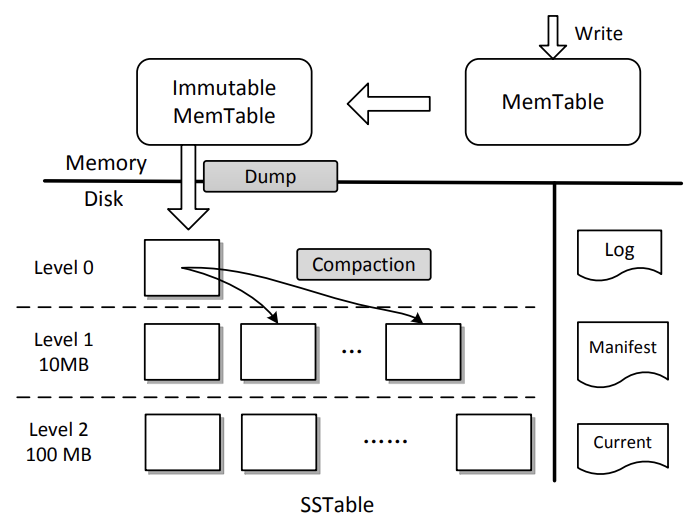
图片来源:https://ranger.uta.edu/~sjiang/pubs/papers/wang14-LSM-SDF.pdf
使用的时候,它的具体文件结构可能如下:
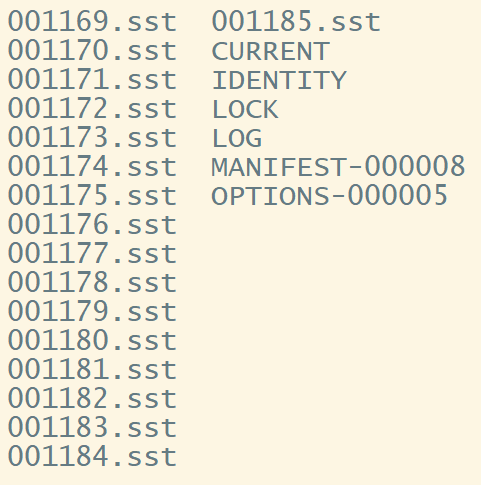
性能
更新动作都是追加的方式,所以性能相对来说非常高。
我目前使用过程中,通过日常性能的观测,一般配置的云盘,顺序读的qps大于50万;
删除的话,删除操作的数据量在亿级的情况下个人感觉并没有那么理想;
随机读的qps,在一些资料中看到能达到20万。
Java代码示例
RocksDB是采用C++编写的,官方提供了Java JNI接口。在实际使用中,提供的有现成的maven依赖。
<dependency><groupId>org.rocksdb</groupId><artifactId>rocksdbjni</artifactId><version>7.9.2</version></dependency>一个基本使用示例如下:
public class RocksDBDemo {public static void main(String[] args) throws RocksDBException {Options options = new Options();options.setCreateIfMissing(true);// 创建rocksdb 客户端RocksDB rocksDB = RocksDB.open(options, System.getProperty("user.dir") + File.separator + "data");String key = "name";String value = "test";// 放入一条数据rocksDB.put(key.getBytes(), value.getBytes());// 查询数据byte[] bytes = rocksDB.get(key.getBytes());System.out.println(value.equals(new String(bytes)));// 删除数据rocksDB.delete(key.getBytes());rocksDB.close();}
}rocksdb看着简单,深度使用,个人感觉门槛还是挺高的。仅仅是它的各项属性了解到心中有数,都是需要花费不少时间成本的。
关于rocksdb的的更多内容,建议查看官方文档。
kafka
kafka是一款高性能的消息中间件,分布式流处理平台。
中文文档:https://kafka.apachecn.org/documentation.html
kafka相对rocksdb,了解或者直接使用的人更多,所以不再具体说明了。
生产实践
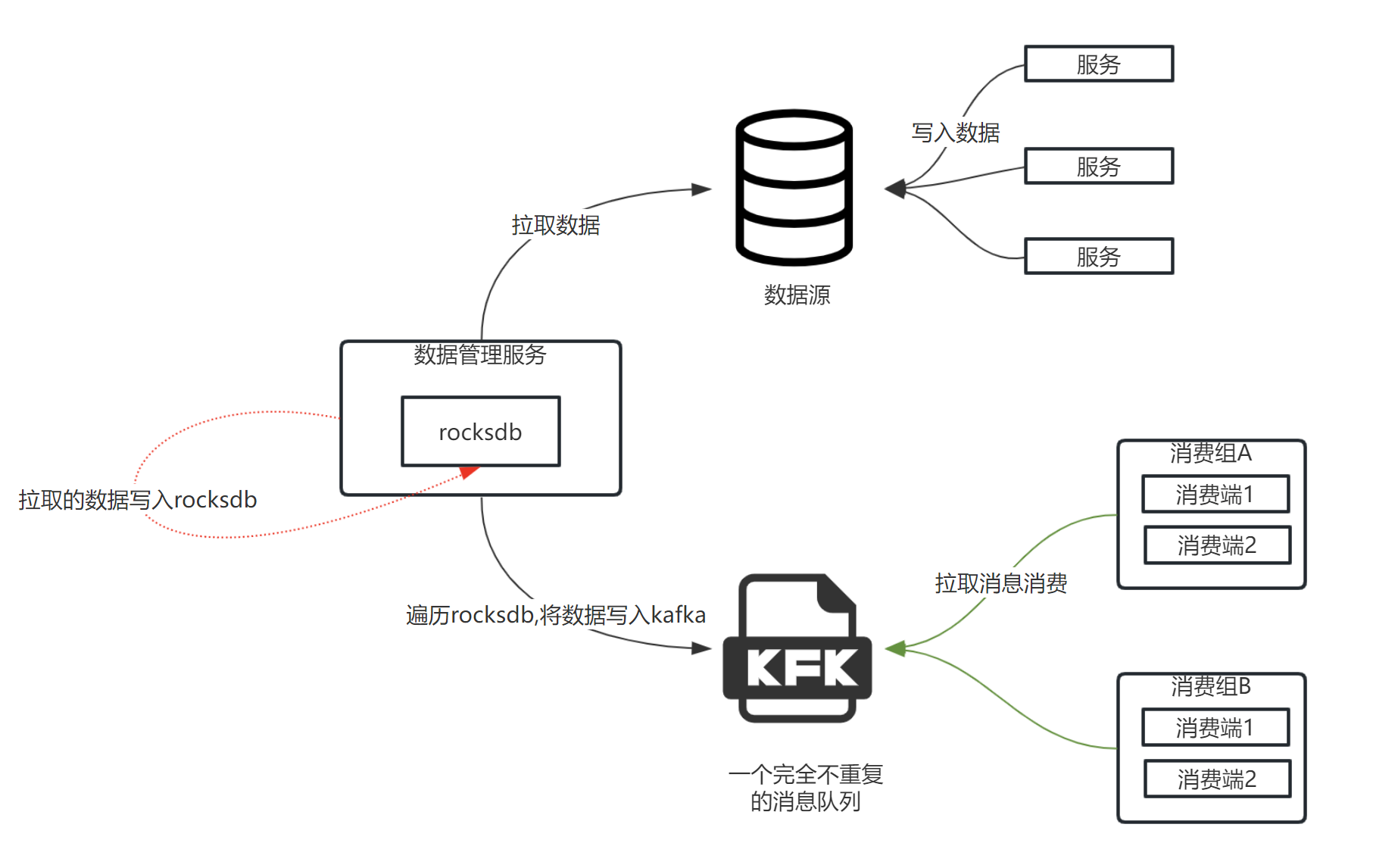
服务部署模型
实现说明
总体流程中,针对rockesdb处理是数据管理服务部分。将指定数据源的数据加载到rocksdb数据库中来实现去重的目的。
对于去重后的数据,在数据量特别大且要求吞吐量高的场景,需要基于调度的方式,将数据加载到kafka的topic中。让消费端来主动拉取处理,kafka这个场景下的吞吐量根据消息体的不同大小,TPS在数十万到上百万不等.
注意,因为要保证数据在kafka上去重要求。所以每次从rocksdb加载数据到kafka的时候,目标topic应该是一个新的,这样保证数据的隔离。
弊端
上面的解决方案适用场景非常狭窄,主要是针对离线计算的场景下,而且对于kafka消费端的业务场景要求也有很大的局限性。
因此,这个方案仅供参考,若是真有相同需求的朋友,希望有所帮助。另外,可以考虑了解下rocksdb,在某个场景中可以作为一个高性能的嵌入式数据库使用。








