您现在的位置是:主页 > news > 动易网站系统怎么样/搜索引擎营销的优缺点及案例
动易网站系统怎么样/搜索引擎营销的优缺点及案例
![]() admin2025/5/6 7:54:09【news】
admin2025/5/6 7:54:09【news】
简介动易网站系统怎么样,搜索引擎营销的优缺点及案例,wordpress 分类目录字数,企业做网站需要租服务器吗最近为我们的游戏服务器接入链路追踪系统,了解了公司内、公司外的多个链路追踪组件,链路追踪系统可以用于监控分布式系统的性能、调用关系、定位问题等。链路追踪中有个很重要的概念叫做OpenTracing,它不是一个可以下载、可以引入的组件或者程序…
最近为我们的游戏服务器接入链路追踪系统,了解了公司内、公司外的多个链路追踪组件,链路追踪系统可以用于监控分布式系统的性能、调用关系、定位问题等。
链路追踪中有个很重要的概念叫做OpenTracing,它不是一个可以下载、可以引入的组件或者程序,而是一种标准,在java里可以理解为定义了一系列链路追踪的interface,各个开发基础组件的公司可以基于这些接口,开发自己的链路追踪系统。而业务开发者,只需要通过opentracing的api来进行业务埋点,具体实现可以随意选择,切换成本非常低,只需要修改数行代码就可以从一个链路追踪组件切换到另一个链路追踪组件;前提就是这些组件是符合Opentracing规范。
后面我将介绍下我们的游戏服务器引入链路追踪系统是解决了什么问题,针对具体的问题,我也会从两方面介绍:
如果没有
Opentracing,我如何去实现,实现方式存在哪些问题Opentracing如何解决上面提到的问题
通过两者的对比,更好的理解Opentracing的设计。
链路追踪有什么用
函数调用监控
随着每个迭代需求的增加,我们的游戏服务器业务代码越来越多,玩家登录需要处理的玩法系统也越来越多,导致登录慢,如何去定位哪一部分耗时最多,从而去优化呢?
假设我们的登录逻辑如下
public void login(User user) {
initBuilding(user); // 建筑
initGodAnimal(user);// 神兽
initArmy(); // 士兵
initFriend(); // 好友
initAlliance(); // 联盟
... // 好几十个其他模块
...
}
最土的办法,加日志
public void login(User user) {
long time = nowTime();
initBuilding(user); // 建筑
log.error("buiding cost:{}", nowTime() - time);
time = nowTime();
initGodAnimal(user);// 神兽
log.error("god animal cost:{}", nowTime() - time);
initArmy(); // 士兵
// log.error....
initFriend(); // 好友
// log.error...
initAlliance(); // 联盟
... // 好几十个其他模块
...
}
稍微优美点的方法,将监控的逻辑构造出一个对象,让监控代码收敛,简洁一些
public void login(User user) {
Monitor mon = new Monitor("login");
initBuilding(user); // 建筑
mon.record("building");
initGodAnimal(user);// 神兽
mon.record("godanimal");
initArmy(); // 士兵
mon.record("Army");
initFriend(); // 好友
...
initAlliance(); // 联盟
... // 好几十个其他模块
...
mon.finish(); // 结束统计,输出结果
}
// Monitor内部维护一个时间和一个stringbuilder对象,封装了统计耗时,输出结果的逻辑,用起来稍微简单些
最终得到的结果就是日志文件,结果如下:
building cost 100ms, god animal cost 200 ms, xxxx cost 300......
这个日志结果存在几个问题:
第一个问题:如果只有三个模块,日志不长,其实看着也还行吧,但是我们服务器现状是,一条日志可以有20行左右,全是这样的xxx cost yyy ms,非常的不直观。
第二个问题:统计颗粒度不够细,比如得出了god animal模块很慢,但是initGodAnimal里可能也包含了很多的逻辑,包含好几次的db、redis查询,我们的追踪日志需要继续的细化。
第三个问题:文本可视化程度不够,方法间调用关系不明确,日志里都属于同一层,体现不出调用关系
如何细化?
日志的方式如何细化
往initBuilding, initGodAnimal函数中像之前一样继续加日志
构造出监控对象的如何继续细化?
// 将mon对象传入每一个子方法,子方法调用Monitor.record继续记录耗时
public void login(User user) {
Monitor mon = new Monitor("login");
initBuilding(mon, user); // 建筑
initGodAnimal(mon, user);// 神兽
initArmy(mon); // 士兵
initFriend(mon); // 好友
// ....
mon.finish(); // 结束统计,输出结果
}
上面的这种做法可以解决问题,但是很不优雅,需要修改几乎所有方法的签名。
Opentracing用法
public void login(User user) {
Tracer tracer = GlobalTracer.get();
Span span = tracer.buildSpan("login").start(); // 构造一个span对象
span.setTag("user_id", user.id); // 可以给span设置一些信息
try (Scope scope = tracer.scopeManager().activate(span)) {
initBuilding(user); // 建筑
initGodAnimal(user);// 神兽
initArmy(); // 士兵
initFriend(); // 好友
...
initAlliance(); // 联盟
... // 好几十个其他模块
...
} finally {
span.finish();// 结束统计
}
}
// initBuilding()
public void initBuilding() {
Tracer tracer = GlobalTracer.get();
Span span = tracer.buildSpan("login").start();
// 业务逻辑
span.finish();
}
// 其他方法类似
这里的Tracer, Span, Scope等都是Opentracing定义的接口
GlobalTracer是一个工具类(也可以自己实现个类似的,这个应该不属于opentracing规范内的东西),可以通过get方法获取一个单例的Tracer对象,前面提到的不同基础组件开发公司,主要开发的就是Tracer的具体实现,我们只需要在程序启动时,将第三方实现好的Tracer对象注入到GlobalTracer中,因此在不同的第三方链路追踪系统之间切换时,只需要修改一下注入对象;而业务代码的埋点逻辑,我们都是基于interface编程,所以无需修改。即使我们在启动服务器时,没有向GlobalTracer中注入任何对象,它内部也默认实现了一个没有任何逻辑的NoopTracer,我们的代码执行也不会有任何异常。通过这种单例模式,可以不需要将 tracer对象作为参数传入每一个需要监控的方法。
一个Span对象就是一条监控记录,与前面自己实现的Monitor不同的地方是,新的代码中构造了很多个Span对象,但是之前的Monitor对象只有一个。Span只关注自己需要监控的代码,比如login方法中的Span,统计的是登录的耗时,比如initBuilding中的span统计的是初始化建筑的耗时。
span的大概结构如下:
public Span {
// 代表一条链路,同一条链路上,所有的span的trace_id相同
// 以上面的登录代码举例
// 一个玩家的一次登录的完整过程算一条链路
// login, building, godAniaml中构造的span的trace_id都是相等的
String traceId;
// 当前span节点的ID,唯一
String spanId;
// 父节点id,表示调用关系
// 以上面登录代码举例
// login节点是所有init方法中父节点
String parentId;
// 其他一些记录监控指标的信息
}
spanId是每个Span节点唯一的,很好生成,不介绍了。但是traceId,parentId这些与上下文相关联的信息如何写入呢?
一条链路,总归会有一个起始节点,对登录来说,就是我们的login方法入口。初始节点就是一个创建traceId的合适地方,因为代表了一条链路的开始。
如何判断是不是链路的起点呢?上面的代码中,其实我们创建span的方法都是一模一样的。区别在于login方法中多了Scope scope = tracer.scopeManager().activate(span)这样的一行代码,而其他init方法中没有。
ScopeManager是上下文管理器,也是一个接口,可以有不同的实现。以大多数java服务器应用的并发模型来说,都是采用多线程的方式。即玩家登录的处理逻辑是靠一个线程池来处理的,一个线程在一段时间内,处理的是同一个玩家的登录请求,登录的整条链路都是在一个线程内处理的(rpc,mysql等远程调用,对本机来说还是一个线程)。则可以把链路的上下文信息放入线程中,即ThreadLocal。
针对于ThreadLocalScopeManager,activate(span)方法就是将当前这个span对象存到线程本地变量中,当下一个Span对象构造时,就判断下当前本地变量里是否已经存在span对象(其实是一个链表结构,因为可以有多层调用),如果存在,则认为线程本地变量中的span对象是自己的父节点,则可以把自己相应的traceId,parentId字段补充完整。并且因为threadLocal的存在,span对象也不需要像上面自己实现的monitor对象一样作为参数传入每一个方法。
ScopeManager一般会实现autoClose接口,所以用try语法糖来实现自动关闭,从而将本地变量中的Span对象删除。
通过ScopeManager对象,就可以体现出不同span之间的调用关系,当我们需要对当前监控的方法的子方法进行调用时,就可以通过ScopeManager来体现出这种调用的父子关系。
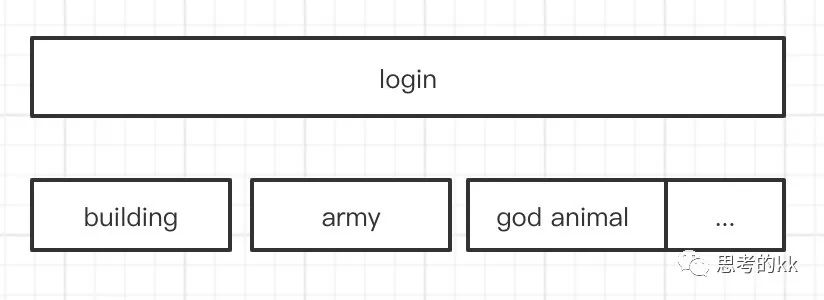
在时序图上,就可以展示出如上图这样的效果,整个login耗时假设100ms,前30ms用来initBuilding,接下里的20ms用于initArmy…不仅每个阶段的耗时可以统计出来,也能把他们的时序顺序,调用关系充分的体现出来。
远程调用监控
上面都在将本地的调用监控,现在的系统大多数是分布式系统,存在各种远程调用,mysql,redis等,这些也是我们需要监控的地方。
拿上面的登录流程举例,我们得知登录流程慢,其实可以以90%以上的信心认为是db查询耗时太慢导致登录耗时久,因为正常的内存操作都是非常快的,不会有太大问题。上面的那种埋点方式,重复代码多,作用其实也不大。因为没有埋在关键点位:rpc调用,mysql,redis这些耗时的操作上。
mysql,redis埋点
db查询由于io和网络延迟的存在,是耗时最严重的地方,也是监控需要重点覆盖的地方。只需要找到这些调用最底层的地方,进行统一埋点构造span对象,就可以监控所有的db操作。前面提到Span对象可以设置tag,在这里可以把db语句等放置进去
rpc埋点
mysql,redis也可以认为是远程调用,但是与一般rpc相比还是存在一些差异。当我们访问mysql和redis时,可以认为mysql,redis服务器就是终点了,它们除了处理我们的请求,不会主动的发起其他的请求或者子调用。
但是rpc服务器就不一样了,比如A服务器调用了B服务器的一个接口,B服务器的处理逻辑也是一条复杂的链路,由多个子调用组成。前面是通过ScopeManager来控制一个进程内不同span之间的调用关系,但是AB服务器不是同一个进程,ScopeManager显然做不到这件事。那么在B服务器中创建的span对象,他的traceId,parentId该如何赋值呢?
B服务器的traceId,parentId应该继承自A服务器,所以需要一个机制,来将A服务器的traceId,parentId来传送给B服务器。
Tracer定义了两个接口来实现不同进程间传递上下文的需求:Tracer.Inject(…) 和 Tracer.Extract(…)。
inject方法可以将上下文信息以指定的方式序列化,rpc client只需要将序列化得到的对象当作rpc调用中的一个参数传出去,rpc server端读取这个参数,将其反序列化得到SpanContext对象,然后rpc server在创建自己的span对象时,基本步骤与之前完全一样,只需要在创建第一个span对象时将得到的spanContext对象设置为自己的父节点(即为自己创建的span对象的traceId,parentId进行赋值)。
最终A,B服务器创建的span对象都会发送到统一的后端服务器。这个服务器则根据traceid,spanid,parentid来将这些单独的span对象相互关联起来,形成调用链。
链路可视化界面
前面提到了,日志形式的监控,可视化非常差,不能让人直观的看出哪个环节慢了,不同模块的调用、时序关系等,但是开源的链路追踪系统,他们的后台可视化界面都非常的清晰。我们的服务器最终选用了uber开源的jaeger来做链路追踪。
以login方法为root span节点(root节点用来将后续所有的子调用关联起来),mysql,redis,rpc最底层通用接口进行埋点,所有init方法无需创建新的span(基于我们对耗时都处于mysql,redis,rpc的判断)
登录效果如下:

可以看出登录总共耗时732ms,mysql和redis总共执行次数为115次,每一次的查询语句,耗时、时序关系在上面都显示的清清楚楚。
有了这个可视化界面可以帮助我们发现很多问题:
某些sql语句耗时明显过大,想办法优化
有几条sql在一次登录中居然出现了十几次,需要优化处理逻辑
参考链接
opentracing官网
opentracing中文文档
opentracing java api








