您现在的位置是:主页 > news > 网页视频怎么下载不了/seo搜索优化 指数
网页视频怎么下载不了/seo搜索优化 指数
![]() admin2025/5/3 20:39:04【news】
admin2025/5/3 20:39:04【news】
简介网页视频怎么下载不了,seo搜索优化 指数,什么网站可以自己做房子设计图,夏都通app下载最新版本Flink 是一个针对流数据和批数据的分布式处理引擎。说起Flink那么必定会和Spark比一比,从slogan来看也能看出来一些区别(详细内容,可以参考下面链接):Apache Flink is an open source platform for distributed stream…
Flink 是一个针对流数据和批数据的分布式处理引擎。说起Flink那么必定会和Spark比一比,从slogan来看也能看出来一些区别(详细内容,可以参考下面链接):
Apache Flink is an open source platform for distributed stream and batch data processing
Apache Spark™ is a fast and general engine for large-scale data processing.
从基本架构来看:

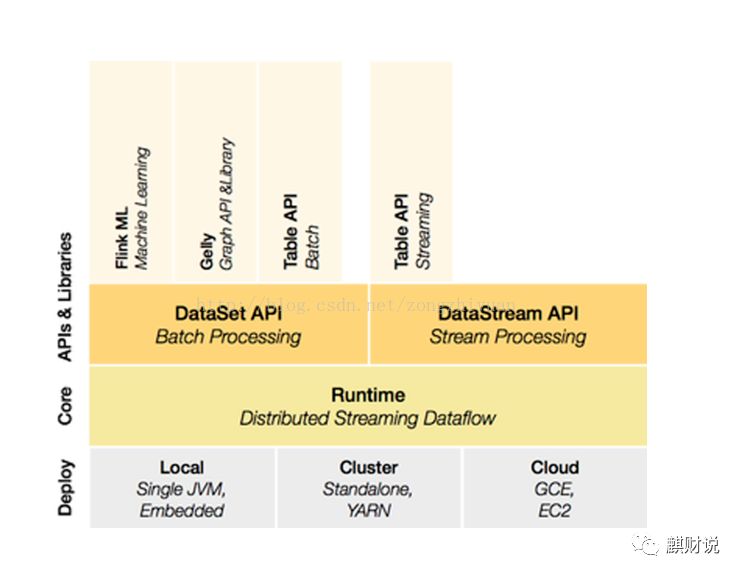
其他一些基本对比,如下表:
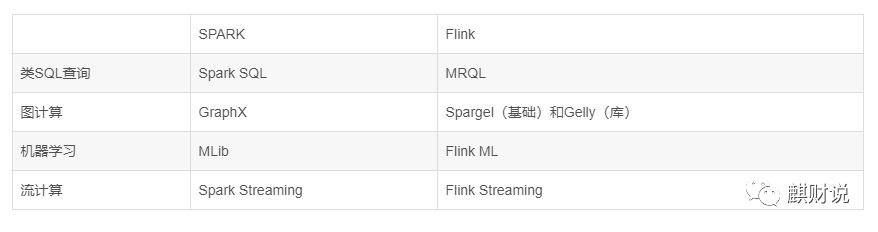
从架构上可以看出,Flink从开始就对off-heap很介意,所以他们一直致力于自己控制内存,而spark是从1.5以后,才尝试开始自己控制内存。其他一些模块各有启发,我也不是历史学家,无从考证,但是个人还是都不太喜欢目前的使用的提交方式。
好了,13装完了,开始撸代码吧....
首先是部署环境,从官方镜像库开始
https://hub.docker.com/_/flink/
划重点,这里尽量使用 docker-compose来运行,它默认就把 flink web端,job manager 和 task manager 都启动好,我就图省事,只启动了flink服务,后面怎么提交任务都执行失败,卡了好半天。
docker-compose up
启动起来了
构建一个基础maven工程,网上习惯用scala,我折腾了半天,尽管最后成功了,但是感觉不是很清楚,而且scala的版本和发行版本需要匹配,这个就很让人恼火,其实主要还是因为不太会吧,java就明了很多,pom如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.dafei1288</groupId>
<artifactId>testjf</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<flink.version>1.6.0</flink.version>
<dependency.scope>compile</dependency.scope>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<index>true</index>
<manifest>
<addClasspath>true</addClasspath>
<mainClass>com.dafei1288.Test</mainClass>
<addDefaultImplementationEntries>true</addDefaultImplementationEntries>
<addDefaultSpecificationEntries>true</addDefaultSpecificationEntries>
</manifest>
<manifestEntries>
<url>${project.url}</url>
<build-time>${maven.build.timestamp}</build-time>
</manifestEntries>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>
划重点,这里最好加上构建jar的plugin,否则提交jar以后还要手动指定入口类。
在我们数据科学家的术语库里,也有个类似Helloworld的东西叫Wordcount,所以来撸一发:
package com.dafei1288;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
//这里注意使用ExecutionEnvironment.getExecutionEnvironment 获取提交环境
final ExecutionEnvironment ee = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> dss =ee.fromElements("111 222","222 333","333","444");
DataSet<Tuple2<String,Integer>> wp = dss.flatMap(
//把输入行串起来并拆分成元组(词,计数器)
new FlatMapFunction<String, Tuple2<String,Integer>>(){
@Override
public void flatMap(String s, Collector<Tuple2<String, Integer>> collector) throws Exception {
for(String word:s.split(" ")){
collector.collect(new Tuple2(word,1));
}
}
})
.groupBy(0)
.sum(1);
wp.print();
}
}
就是这么简单,如果用scala,可就麻烦多了,如果你不了解,就先别坑爹了,这个难度正好。
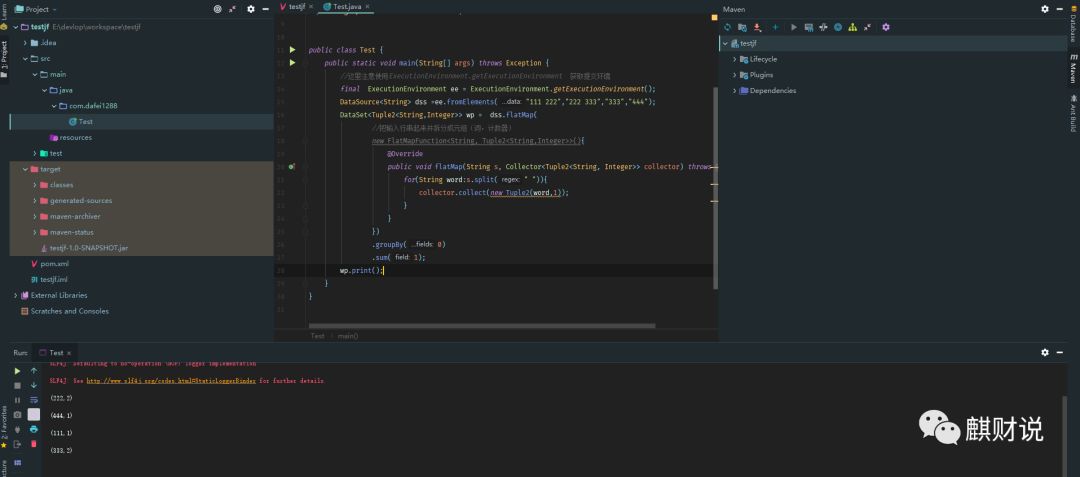
本地执行,轻松愉快, 接下来,
mvn package
来打包程序,然后上传

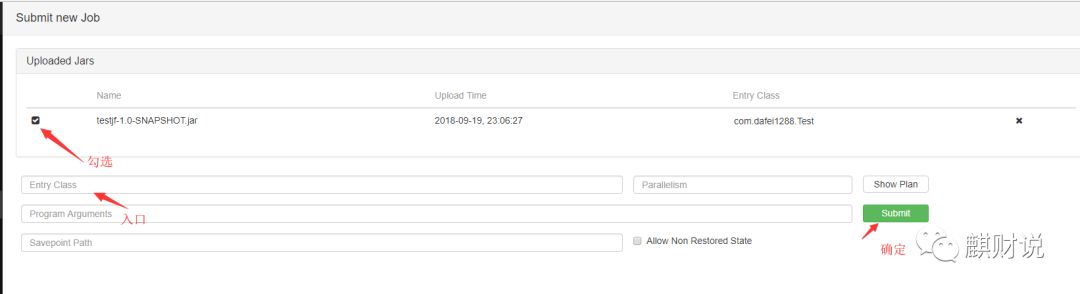
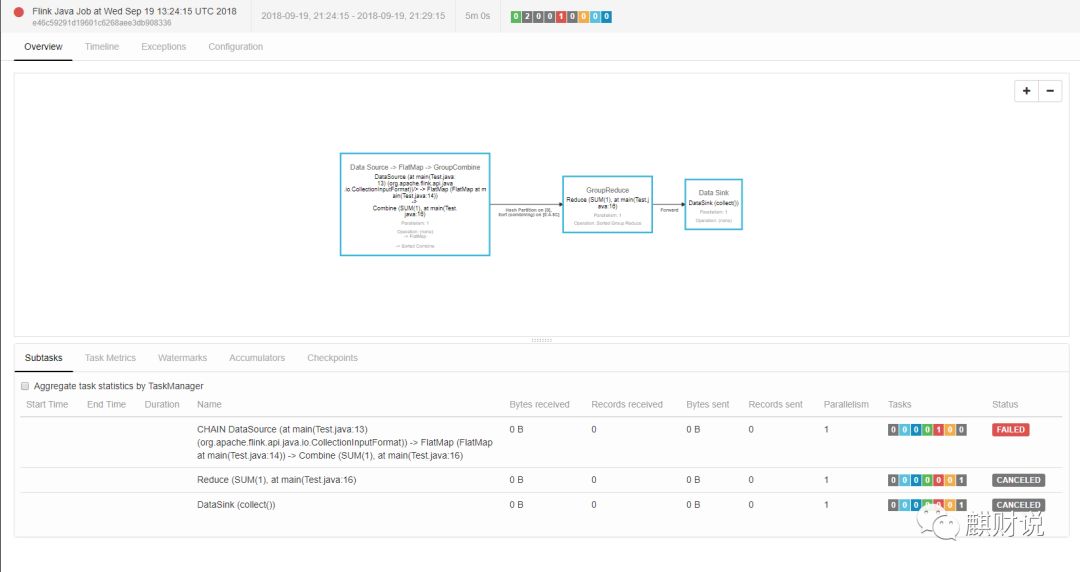
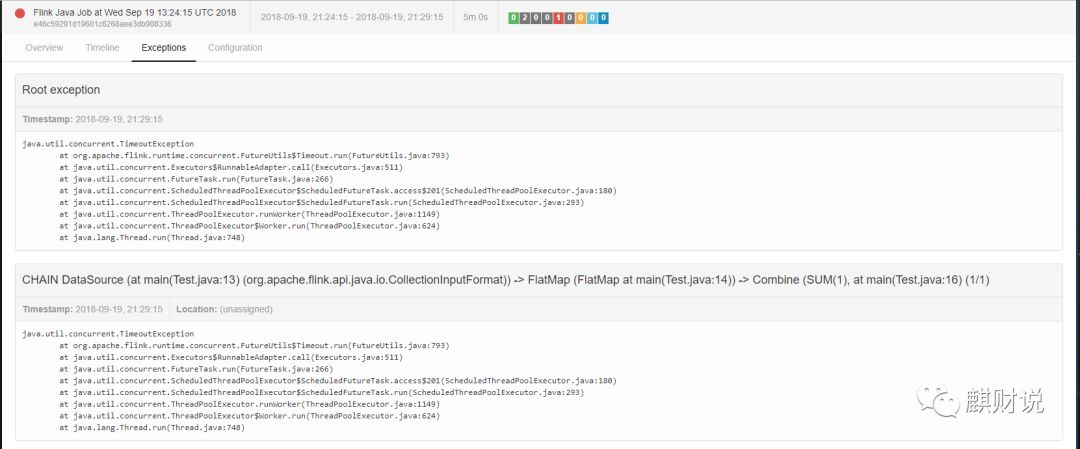
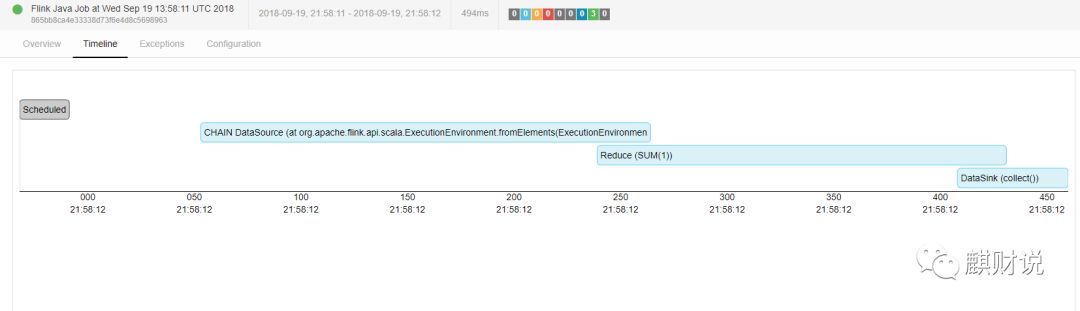
在前面说过,如果没启动job和task就会出现下面的错误:
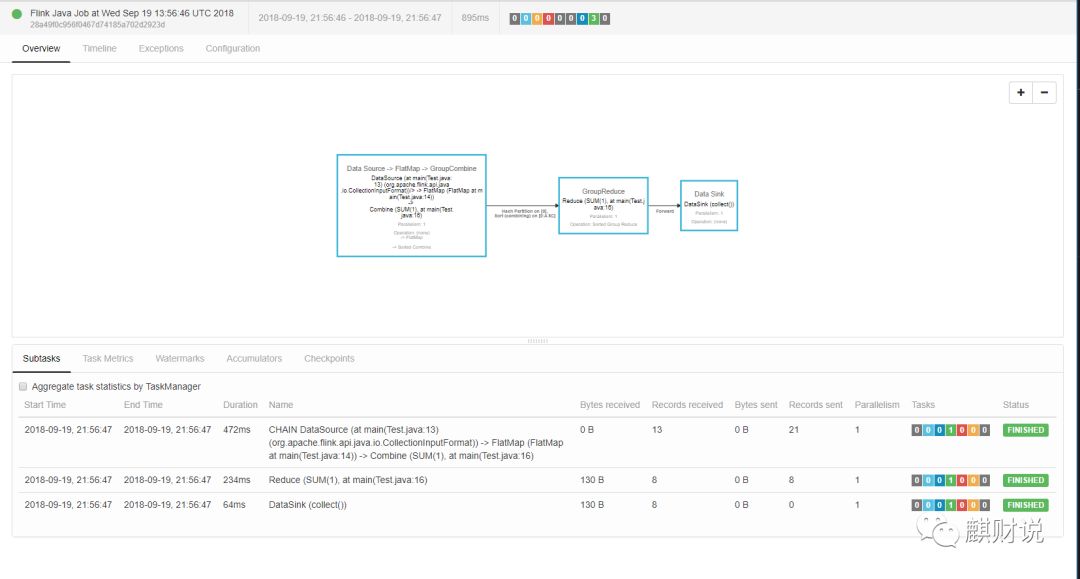
正常的执行,会是这样的
好了,科(躲)普(坑)报告完成。
参考文献:
https://stackoverflow.com/questions/28082581/what-is-the-difference-between-apache-spark-and-apache-flink
https://blog.csdn.net/xuly_29/article/details/80061784








