您现在的位置是:主页 > news > 做企业网站需要做什么/百度知道提问首页
做企业网站需要做什么/百度知道提问首页
![]() admin2025/5/4 17:24:30【news】
admin2025/5/4 17:24:30【news】
简介做企业网站需要做什么,百度知道提问首页,网站和做游戏,北京到安阳高铁时刻表01研究背景本章是基于Lasso回归筛选变量后,构建Cox回归临床预测模型,并绘制Nomogram图。Cox模型是一种半参数模型,该模型以生存结局和生存时间为因变量,分析多个因素对生存期的影响,常用RR来量化这种结果,绘…
01
研究背景
本章是基于Lasso回归筛选变量后,构建Cox回归临床预测模型,并绘制Nomogram图。Cox模型是一种半参数模型,该模型以生存结局和生存时间为因变量,分析多个因素对生存期的影响,常用RR来量化这种结果,绘制Nomogram列线图实现个体预测。有关Lasso回归可见公众号前文章介绍。
02
案例研究
本文数据收集了83例癌症患者的生存资料,包含患者年龄、性别、癌症分期等。研究目的探讨癌症患者生存情况的影响因素并构建预测模型。
临床研究一般有提供多个危险因素,首先做单因素的筛选,具体筛选方法,见公众号之前的文章。本文采用Lasso回归筛选因素。具体分析步骤是①筛选变量②基于这些变量构建模型③绘制Nomogram图,预测不同时间生存概率。③计算模型c_index(区分度)该步骤用神包rms一步实现。接下来直接上代码。
03
R代码及解读
##加载包 明确每个包的作用library(glmnet) ##Lasso回归library(rms) ## 画列线图;library(VIM) ## 包中aggr()函数,判断数据缺失情况library(survival) ## 生存分析包#读取数据集dt str(dt) ##查看每个变量结构 aggr(dt,prop=T,numbers=T) #判断数据缺失情况,红色表示有缺失。 dt 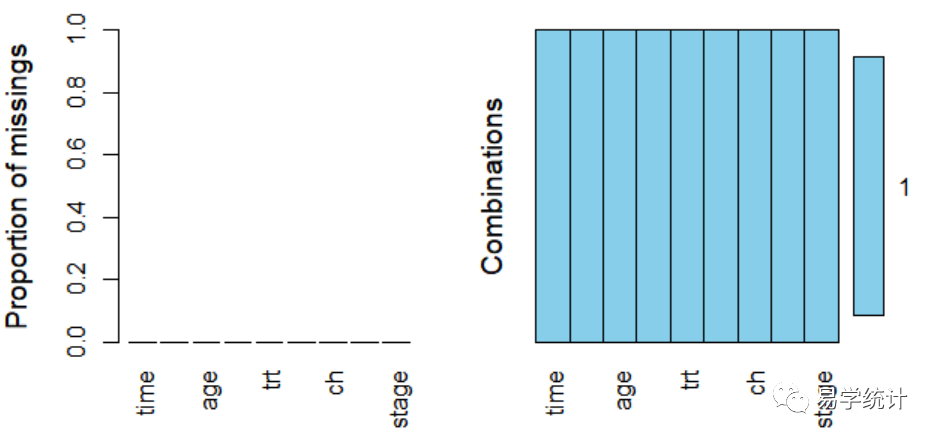
由图片可看到所有变量都为蓝色,没有缺失值。如果用na.omit()函数按照行删除。
第一步,也是很重要的一步,数据整理。
#用for循环语句将数值型变量转为因子变量for(i in names(dt)[c(4:9)]) {dt[,i] ##筛选变量前,首先将自变量数据(因子变量)转变成矩阵(matrix)x.factors ~ dt$sex+dt$trt+dt$bui+dt$ch+dt$p+dt$stage,dt)[,-1]#将矩阵的因子变量与其它定量边量合并成数据框,定义了自变量。x 3]))#设置应变量,打包生存时间和生存状态(生存数据)y $time,dt第二步:Lasso回归筛选变量
#调用glmnet包中的glmnet函数,注意family那里一定要制定是“cox”,如果是做logistic需要换成"binomial"。fit "cox",alpha = 1)plot(fit,label=T)plot(fit,xvar="lambda",label=T)#主要在做交叉验证,lassofitcv "cox", alpha=1,nfolds=10)plot(fitcv)coef(fitcv, s="lambda.min")###9 x 1 sparse Matrix of class "dgCMatrix" 1##d.sex1 . ##d.trt1 . ##d.bui1 . ##d.ch2 . ##d.ch3 . ##d.ch4 -0.330676##d.p1 . ##d.stage4 . ##d...3. .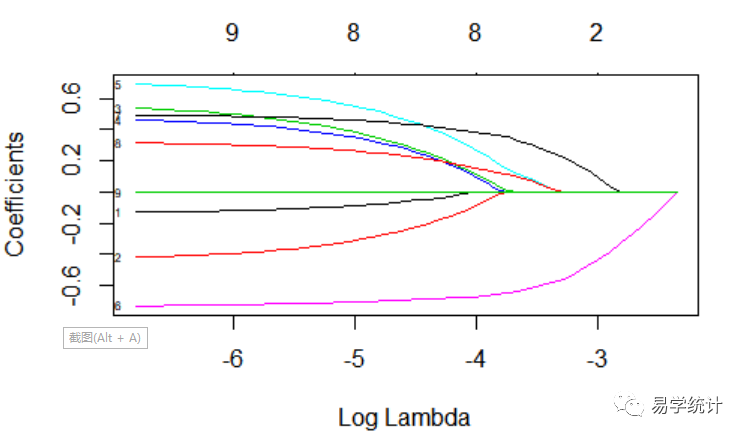
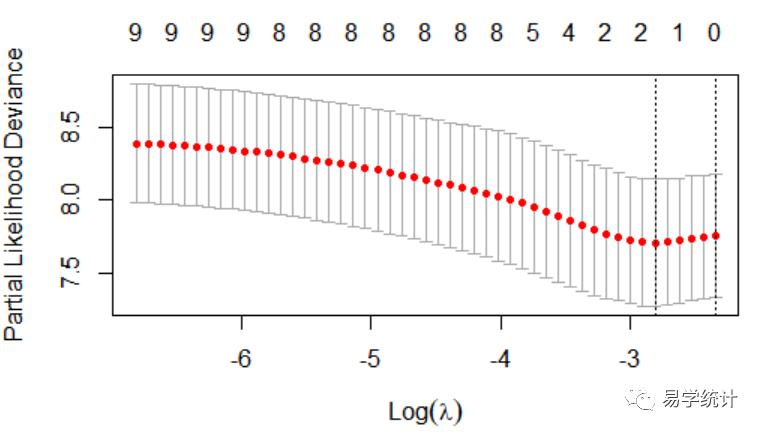
该图在之前文章提到,见如何进行高维变量筛选和特征选择(一)?Lasso回归,由上述代码以及图片完成变量筛选,这里只做演示,假设所有的变量都入选了,我们用这些入选的变量构建Cox回归模型。
第三步:构建Cox模型,并检验等比例风险
#拟合cox回归coxm <- cph(Surv(time,censor==1)~age+sex+trt+bui+ch+p+stage,x=T,y=T,data=dt,surv=T) cox.zph(coxm)#等比例风险假定## chisq df p##age 1.993 1 0.158##sex 0.363 1 0.547##trt 3.735 1 0.053##bui 2.587 1 0.108##ch 0.296 1 0.587##p 0.307 1 0.579##stage 0.395 1 0.530##GLOBAL 9.802 7 0.200注意chp()函数的写法,其中因变量需要用Surv()先打包。后面写法同LR。
等比例风险检验:最后面的GLOBAL是整体看,P值大于0.05,全模型整体都是满足的。对于每一个分类来说P值大于0.05,也是满足的。
第四步:绘制nomogram图,注意该函数里面的参数设置。
###开始cox nomo graphsurv # 建立生存函数surv1 x)surv(surv2 x)surv(surv3 x)surv(dd#设置工作环境变量,将数据整合options(datadist='dd') #设置工作环境变量,将数据整合plot(nomogram(coxm, fun=list(surv1,surv2,surv3), lp= F, funlabel=c('3-Month Survival','6-Month survival','12-Month survival'), maxscale=100, fun.at=c('0.9','0.85','0.80','0.70','0.6','0.5','0.4','0.3','0.2','0.1')), xfrac=.45)#maxscale 参数指定最高分数,一般设置为100或者10分#fun.at 设置生存率的刻度#xfrac 设置数值轴与最左边标签的距离,可以调节下数值观察下图片变化情况plot(nomogram)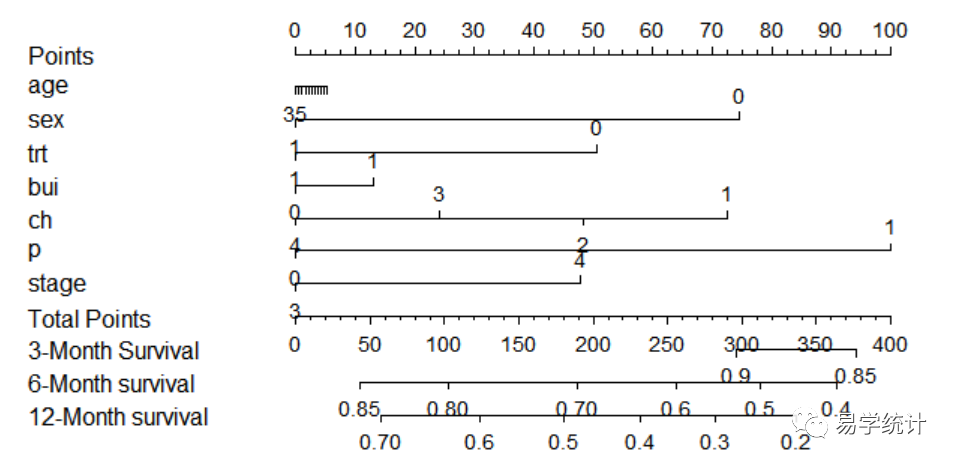
该图的使用,本质上是将Cox回归模型可视化展示,方便临床快速判断。假设有个病人性别为女,trt为0,P期为1,Nomogram用法是在sex变量上找到其值为1的刻度,然后画垂线投影到最上方的points刻度尺上,找到对应的分值为75分,同理找到trt为0的分值约为50分,P为1的对应分值为100,将这三个因素的points值加起来总分225。下一步在下面的Total Points刻度尺上找到225分,向下方的3个轴做垂线,6-Month-survival对应的值在0.6和0.7之间,约为0.65,说明该患者6个月的生存概率值为65%,其他以此类推。
第三步:利用rms包计算模型区分度。
##模型验证#Concordance indexf1)~age+sex+trt+bui+ch+p+stage,data=d)sum.survc_indexc_index ####C se(C) ##0.55396619 0.07664425该模型的区分度C-index为0.554,其本质同ROC曲线面积。结果显示,该模型的区分度一般。根据前面变量筛选,考虑纳入更多的影响因素和样本。
04
参考文献
方积乾等. 卫生统计学. 人民卫生出版社。
薛毅等.统计建模与R软件.清华大学出版社
作者介绍:医疗大数据统计分析师,擅长R语言。
更多阅读:
如何进行高维变量筛选和特征选择(一)?Lasso回归
R语言Logistic回归模型深度验证以及Nomogram绘制