您现在的位置是:主页 > news > 介休做网站/网上推广怎么做
介休做网站/网上推广怎么做
![]() admin2025/5/2 17:15:29【news】
admin2025/5/2 17:15:29【news】
简介介休做网站,网上推广怎么做,网站数据库特点,网站的功能需求分析欢迎关注 “小白玩转Python”,发现更多 “有趣”什么是图像增强?图像增强,解决数据有限的问题。图像增强是一种通过在数据集中人工扩大训练数据集大小的技术。图像增强包括一系列技术,这些技术可以增强训练图像的大小和质量&#…
介休做网站,网上推广怎么做,网站数据库特点,网站的功能需求分析欢迎关注 “小白玩转Python”,发现更多 “有趣”什么是图像增强?图像增强,解决数据有限的问题。图像增强是一种通过在数据集中人工扩大训练数据集大小的技术。图像增强包括一系列技术,这些技术可以增强训练图像的大小和质量&#… 
欢迎关注 “小白玩转Python”,发现更多 “有趣”
什么是图像增强?图像增强,解决数据有限的问题。图像增强是一种通过在数据集中人工扩大训练数据集大小的技术。图像增强包括一系列技术,这些技术可以增强训练图像的大小和质量,从而可以用它们训练更好的深度学习模型。
base_dir = os.path.join("/kaggle/input/rock-paper-scissors-dataset/Rock-Paper-Scissors/")# Train settrain_dir = os.path.join(base_dir + "train")print("Train set --> ", os.listdir(train_dir))# Test settest_dir = os.path.join(base_dir + "test")print("Test set --> ", os.listdir(test_dir))# Validation setvalidation_dir = os.path.join(base_dir + "validation")print("Validation set --> ", os.listdir(validation_dir)[:3])Train set --> ['paper', 'scissors', 'rock']Test set --> ['paper', 'scissors', 'rock']Validation set --> ['paper8.png', 'paper1.png', 'scissors-hires1.png']fig, ax = plt.subplots(1, 3, figsize=(15, 10))sample_paper = random.choice(os.listdir(train_dir + "paper"))image = load_img(train_dir + "paper/" + sample_paper)ax[0].imshow(image)ax[0].set_title("Paper")ax[0].axis("Off")sample_rock = random.choice(os.listdir(train_dir + "rock"))image = load_img(train_dir + "rock/" + sample_rock)ax[1].imshow(image)ax[1].set_title("Rock")ax[1].axis("Off")sample_scissor = random.choice(os.listdir(train_dir + "scissors"))image = load_img(train_dir + "scissors/" + sample_scissor)ax[2].imshow(image)ax[2].set_title("Scissor")ax[2].axis("Off")plt.show()
· Con 层: 这一层将提取图像的重要特征
· Pooling 层: 这一层通过隔离重要特征,减少卷积后输入图像的空间体积
· Flatten 层: 将输入“压平”为一维数组
· Hidden 层: 将网络从一层连接到另一层
· Output 层: 网络的最后一层,神经元的个数等于待分类的类别
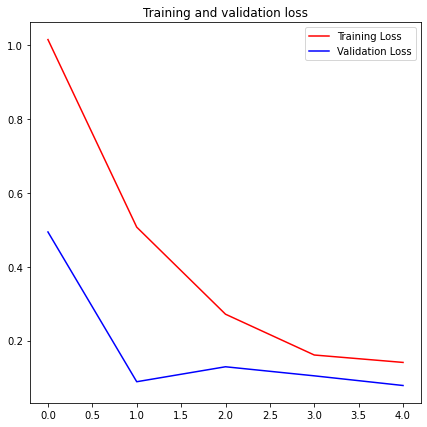
这里,我们有三类图像,所以,输出层应该有三个神经元。model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2, 2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(128, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(3, activation='softmax')])model.summary()Model: "sequential"_________________________________________________________________Layer (type) Output Shape Param # =================================================================conv2d (Conv2D) (None, 148, 148, 32) 896 _________________________________________________________________max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0 _________________________________________________________________conv2d_1 (Conv2D) (None, 72, 72, 64) 18496 _________________________________________________________________max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0 _________________________________________________________________conv2d_2 (Conv2D) (None, 34, 34, 128) 73856 _________________________________________________________________max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0 _________________________________________________________________conv2d_3 (Conv2D) (None, 15, 15, 128) 147584 _________________________________________________________________max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0 _________________________________________________________________flatten (Flatten) (None, 6272) 0 _________________________________________________________________dense (Dense) (None, 512) 3211776 _________________________________________________________________dense_1 (Dense) (None, 1) 513 =================================================================Total params: 3,453,121Trainable params: 3,453,121Non-trainable params: 0model.compile(loss = 'categorical_crossentropy', optimizer = 'adam', metrics = ['accuracy'])class myCallback(tf.keras.callbacks.Callback): def on_epoch_end(self, epoch, logs={}): if(logs.get('accuracy')>0.95): print("\nReached >95% accuracy so cancelling training!") self.model.stop_training = True callbacks = myCallback()train_datagen = ImageDataGenerator( rescale=1./255, rotation_range=40, width_shift_range=0.2, # Shifting image width by 20% height_shift_range=0.2,# Shifting image height by 20% shear_range=0.2, # Shearing across X-axis by 20% zoom_range=0.2, # Image zooming by 20% horizontal_flip=True, fill_mode='nearest')train_generator = train_datagen.flow_from_directory( train_dir, target_size = (150, 150), class_mode = 'categorical', batch_size = 20)Found 2520 images belonging to 3 classes.validation_datagen = ImageDataGenerator(rescale=1./255)validation_generator = validation_datagen.flow_from_directory( test_dir, target_size = (150, 150), class_mode = 'categorical', batch_size = 20)Found 372 images belonging to 3 classes.history = model.fit_generator( train_generator, steps_per_epoch = np.ceil(2520/20), # 2520 images = batch_size * steps epochs = 10, validation_data=validation_generator, validation_steps = np.ceil(372/20), # 372 images = batch_size * steps callbacks=[callbacks], verbose = 2)Epoch 1/10126/126 - 46s - loss: 1.0141 - accuracy: 0.4591 - val_loss: 0.4937 - val_accuracy: 0.9301Epoch 2/10126/126 - 27s - loss: 0.5067 - accuracy: 0.7968 - val_loss: 0.0886 - val_accuracy: 0.9785Epoch 3/10126/126 - 27s - loss: 0.2712 - accuracy: 0.9056 - val_loss: 0.1290 - val_accuracy: 0.9624Epoch 4/10126/126 - 27s - loss: 0.1608 - accuracy: 0.9393 - val_loss: 0.1045 - val_accuracy: 0.9597Epoch 5/10Reached >95% accuracy so cancelling training!126/126 - 26s - loss: 0.1408 - accuracy: 0.9512 - val_loss: 0.0784 - val_accuracy: 0.9677acc = history.history['accuracy']val_acc = history.history['val_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']epochs = range(len(acc))plt.figure(figsize=(7,7))plt.plot(epochs, acc, 'r', label='Training accuracy')plt.plot(epochs, val_acc, 'b', label='Validation accuracy')plt.title('Training and validation accuracy')plt.legend()plt.figure(figsize=(7,7))plt.plot(epochs, loss, 'r', label='Training Loss')plt.plot(epochs, val_loss, 'b', label='Validation Loss')plt.title('Training and validation loss')plt.legend()plt.show()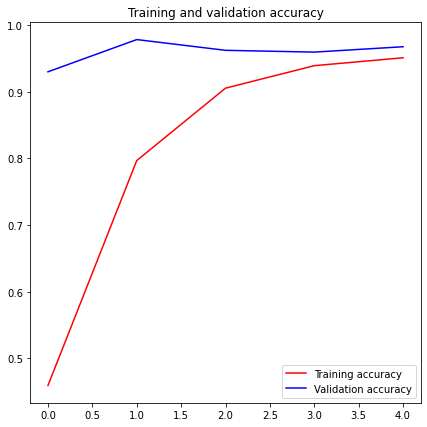
test_img = os.listdir(os.path.join(validation_dir))test_df = pd.DataFrame({'Image': test_img})test_df.head()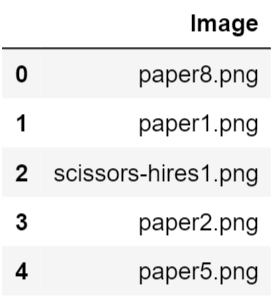
test_gen = ImageDataGenerator(rescale=1./255)test_generator = test_gen.flow_from_dataframe( test_df, validation_dir, x_col = 'Image', y_col = None, class_mode = None, target_size = (150, 150), batch_size = 20, shuffle = False)Found 33 validated image filenames.predict = model.predict_generator(test_generator, steps = int(np.ceil(33/20)))# Identifying the classeslabel_map = dict((v,k) for k,v in train_generator.class_indices.items())print(label_map){0: 'paper', 1: 'rock', 2: 'scissors'}test_df['Label'] = np.argmax(predict, axis = -1) # axis = -1 --> To compute the max element index within list of liststest_df['Label'] = test_df['Label'].replace(label_map)test_df.Label.value_counts().plot.bar(color = ['red','blue','green'])plt.xticks(rotation = 0)plt.show()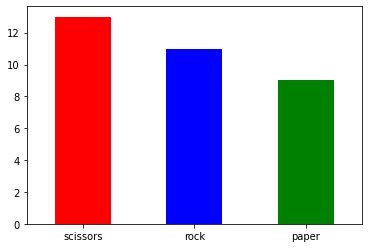
v = random.randint(0, 25)sample_test = test_df.iloc[v:(v+18)].reset_index(drop = True)sample_test.head()plt.figure(figsize=(12, 24))for index, row in sample_test.iterrows(): filename = row['Image'] category = row['Label'] img = load_img(validation_dir + filename, target_size = (150, 150)) plt.subplot(6, 3, index + 1) plt.imshow(img) plt.xlabel(filename + ' ( ' + "{}".format(category) + ' )' )plt.tight_layout()plt.show()
lis = []for ind in test_df.index: if(test_df['Label'][ind] in test_df['Image'][ind]): lis.append(1) else: lis.append(0) print("Accuracy of the model on test data is {:.2f}%".format((sum(lis)/len(lis))*100))Accuracy of the model on test data is 93.94%· END ·
HAPPY LIFE








